Обзор алгоритмов распознавания речи
Ввод речи и цифровая обработка
Для анализа речи её необходимо преобразовать в форму, понятную вычислительной системе. Это может быть аналоговая форма, цифровая форма, спектральное представление, представление в виде оптического излучения и т.д. Так как в работе затрагивается только моделирования систем анализа речи на персональном компьютере, то рассматривается только один вид представления звука – в цифровой форме. Для представления акустического сигнала в цифровой форме практически во всех системах, имеющих дело со звуком, используется импульсная модуляция. Как известно, звук представляет собой продольные волны разрежения-сжатия, распространяющиеся в акустичеки-проводящей среде. Посредством звукозаписывающих устройств (например, микрофона) он преобразуется в электрический сигнал, колебания которого повторяют звуковые колебания (рис 2).
Ввод звука в компьютер
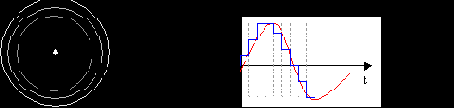
Рис. 2
Затем этот сигнал фильтруется с целью отсечения частот, превышающих некоторую частоту fmax. После этого он подается на аналого-цифровой преобразователь, который с некоторой частотой fd, называемой частотой дискретизации, записывает текущий уровень сигнала в цифровой форме, т.е. квантует сигнал по времени и по амплитуде. Как следует из теоремы Колесникова,
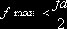
Таким образом, параметрами, определяющими качество оцифровки сигнала, являются частота дискретизации (fd) и разрядность преобразования (сколько единиц информации кодирует один отсчет). Частота дискретизации определяет максимальную частоту сигнала, которую можно записать. Типичные значения - 11025, 22050, 44100 Гц. От разрядности зависит точность кодирования информации при аналого-цифровом преобразовании. Типичные значения – 4 бит, 8 бит, 16 бит на отсчет. Естественно, чем больше разрядность и частота дискретизации, тем точнее записывается звук, но и тем больше поток информации и тем сложнее его записать или обработать. Технические вопросы ввода звука в компьютер в разрабатываемой системе подробно рассматриваются в приложении 7.5.
Предварительная обработка и выделение первичных признаков
Речевой сигнал, поступающий в систему распознавания речи, подвергается предварительной обработке с целью компенсации погрешностей ввода звука и учета специфики сигнала. Как правило, такая обработка заключается в очистке сигнала от шума (например, отсечением неинформативных участков спектра), фильтрации, нормализацией до некоторого установленного уровня.
Затем необходимо выделить информативные признаки речевого сигнала, т.е. те, которые наиболее полно описывают сигнал в наиболее краткой форме. Очевидно, эффективность этого этапа определяет эффективность дальнейшей обработки сигнала и его распознавание. Понятно, что временное представление сигнала является довольно неэффективным, т.к. во-первых, не учитывает периодичности звука, во-вторых, из-за большой изменчивости речи даже один и тот же звук, произнесенный одним и тем же человеком, сильно варьируется в его временном представлении.
Гораздо более информативно спектральное представление речи. Для получения спектра используют набор полосовых фильтров, настроенных на выделение различных частот, или дискретное преобразование Фурье. Затем полученный спектр подвергается различным преобразованиям, например, логарифмическое изменение масштаба (как в пространстве амплитуд, так и в пространстве частот), сглаживание спектра с целью выделения его огибающей, кепстральному анализу (обратное преобразование Фурье от логарифма прямого преобразования, см. [3], Cepstral analysis). Это позволяет учесть некоторые особенности речевого сигнала – понижение информативности высокочастотных участков спектра, логарифмическую чувствительность человеческого уха, и т.д.
Как правило, полное описание речевого сигнал только его спектром невозможно. Наряду со спектральной информацией, необходима ещё и информация о динамике речи. Для её получения используют дельта-параметры, представляющие собой производные по времени от основных параметров.
Полученные таким образом параметры речевого сигнала считаются его первичными признаками и представляют сигнал на дальнейших уровнях его обработки.
Выделение примитивов речи
Под примитивами речи понимается неделимые звуки речи – фонемы, из которых и образуется сложная речь (относительно количества фонем идут постоянные споры: по некоторым данным, в русском языке 43 фонемы, по другим – 64, по третьим – более 100). Выделение и распознавание этих примитивов – первый этап распознавания в большинстве существующих систем. От его эффективности во многом зависит дальнейший ход распознавания на последующих этапах.
В случае применения нейросетей обучение выделению примитивов речи может заключаться в формировании нейронных ансамблей, ядра которых соответствуют наиболее частой форме каждого примитива [6]. Формирование нейронных ансамблей – это процесс обучения без учителя, при котором происходит статистическая обработка всех поступающих на вход нейросети сигналов. При этом формируются ансамбли, соответствующие наиболее часто встречающимся сигналам. Запоминание редких сигналов происходит позже и требует подключения механизма внимания или иного контроля с высших уровней.
Распознавание сложных звуков, слов, фраз, и т.д.
Для распознавания слитной речи наиболее простой и понятной является построение системы в виде иерархии уровней, на каждом из которых распознаются звуки все большей сложности: на первом – фонемы, на втором – слоги, затем слова, фразы, и т.д. На каждом уровне сигнал кодируется представителями предыдущих уровней. При переходе с уровня на уровень помимо представителей сигналов передаются и некоторые дополнительные признаки, временные зависимости и отношения между сигналами. Собирая сигналы с предыдущих уровней, высшие уровни располагают большим объемом информации (или её другим представлением), и могут осуществлять управление процессами на низших уровнях, например, с привлечением механизма внимания (см. приложение 7.3).