Ввод звукового сигнала
Ввод звука осуществляется в реальном времени через звуковую карту или через файлы формата Microsoft Wave в кодировке PCM (разрядность 16 бит, частота дискретизации 22050 Гц). Работа с файлами предпочтительней, так как позволяет многократно повторять процессы их обработки нейросетью, что особенно важно при обучении.
Процесс ввода звука изображен на рисунке 8:
Ввод звука
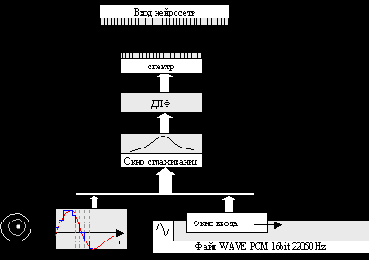
Рис. 8
При обработке файла по нему перемещается окно ввода, размер которого равен размеру окна дискретного преобразования Фурье (ДПФ) – N элементов. Смещение окна относительно предыдущего положения можно регулировать. В каждом положении окна оно заполняется данными типа short (система работает только со звуком, в котором каждый отсчет кодируется 16 битами). После ввода данных в окно перед вычислением ДПФ на него накладывается окно сглаживания Хэмминга:

где Data – массив данных
newData – массив данных, полученный после наложения окна сглаживания
N – размер ДПФ
Наложение окна Хэмминга немного понижает контрастность спектра, но позволяет убрать боковые лепестки резких чстот (рис 9), при этом особенно хорошо проявляется гармонический состав речи.
Действие окна сглаживания Хэмминга (логарифмический масштаб)
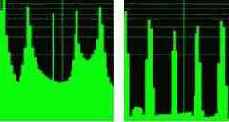
без окна сглаживания с окном сглаживания Хэмминга
Рис 9
После этого выполняется дискретное преобразование Фурье по алгоритму быстрого преобразования Фурье [4]. В результате в реальных и мнимых коэффициентах получается амплитудный спектр и информация о фазе. Информация о фазе отбрасывается и вычисляется энергетический спектр:

где E[i] – энергии частот
Так как звуковые данные не содержат мнимой части , то по свойству ДПФ результат получается симметричным, т.е. E[i] = E[N-i]. Таким образом, размер информативной части спектра NS равен N/2.
Все вычисления в нейросети производятся над числами с плавающей точкой и большинство сигналов ограничены диапазоном [0.0,1.0], поэтому полученный спектр нормируется на 1.0.
Для этого каждый компонент вектора делится на его длину:


Информативность различных частей спектра неодинакова: в низкочастотной области содержится больше информации, чем в высокочастотной. Поэтому для предотвращения излишнего расходования входов нейросети необходимо уменьшить число элементов, получающих информацию с высокочастотной области , или, что тоже самое, сжать высокочастотную область спектра в пространстве частот. Наиболее распространенный метод благодаря его простоте – логарифмическое сжатие, или mel-сжатие (см. [3], “ Non-linear frequency scales”):

где f – частота в спектре, Гц,
m – частота в новом сжатом частотном пространстве
Процесс логарифмического сжатия проиллюстрирован рисунком 10:
Нелинейное преобразование спектра в пространстве частот
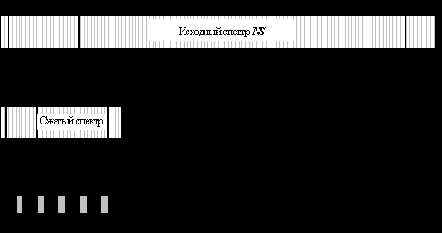
Рис. 10
Такое преобразование имеет смысл, только если число элементов во входе нейросети NI меньше числа элементов спектра NS.
После нормирования и сжатия спектр накладывается на вход нейросети. Вход нейросети – это линейно упорядоченный массив элементов, которым присваиваются уровни соответствующих частот в спектре. Эти элементы не выполняют никаких решающих функция, а только передают сигналы дальше в нейросеть. Наложение спектра на каждый входной элемент происходит путем усреднения данных из некоторой окрестности, центром которой является проекция положения этого элемента в векторе входов на вектор спектра (рис. 10). Радиус окрестности выбирается таким, чтобы окрестности соседних элементов перекрывались. Этот прием часто используется при растяжении/сжатии векторов, (например, изображений), предотвращая «выпадение» данных. Полученный результат очень похож на действие полосовых фильтров, каждый из которых выделяет определенную полосу частот, а все вместе они перекрывают весь полезный спектр частот.
Выбор числа входов – сложная задача, потому что при малом размере входного вектора возможна потеря важной для распознавания информации, а при большом существенно повышается сложность вычислений (только при моделировании на PC, в реальных нейросетях это неверно, т.к.
все элементы работают параллельно).
При большой разрешающей способности ( большом числе) входов возможно выделение гармонической структуры речи и как следствие определение высоты голоса. При малой разрешающей способности (малом числе) входов возможно только определение формантной структуры.
Как показало дальнейшее исследование этой проблемы, для распознавания уже достаточно только информации о формантной структуре. Фактически, человек одинаково распознает нормальную голосовую речь и шепот, хотя в последнем отсутствует голосовой источник. Голосовой источник дает дополнительную информацию в виде интонации (изменением высоты тона на протяжении высказывания), и эта информация очень важна на высших уровнях обработки речи. Но в первом приближении можно ограничиться только получением формантной структуры, и для этого с учетом сжатия неинформативной части спектра достаточное число входов выбрано в пределах 10~50.
После наложения сигнала на вход нейросети начинается его обработка нейросетью. Подробно работа нейросети описана в разделе 5.2.